
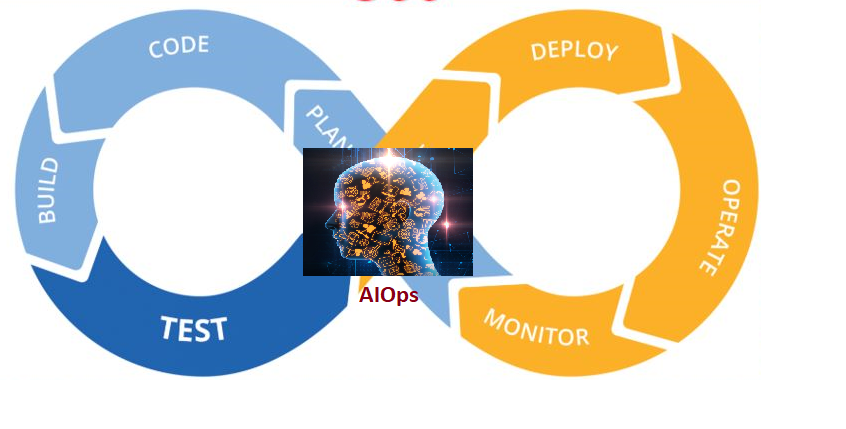
After a successful article on DevSecOps, here I am with an another article where we will explore Artificial Intelligence in IT Ops area. We have addressed one aspect of standing up infrastructure by treating Infrastructure as a Code. Which stand up infrastructure automatically and reduces the IT operation expenditure cycles from days to minutes. There is second aspect where IT Operations is heavily involved i.e. ongoing maintenance activities. It is measured in terms DevOps KPIs which includes Mean Time to Detect (MTTD),Mean Time to Failure (MTTF) & Mean Time to Resolve (MTTR). AIOPs is advanced way to address part of the problem and we will explore it in rest of article.
AIOps terminology was coined by Gartner but the need & fulfillment of those automation need in Ops area was achieved from a long time in a crude way. But recent breakthrough in multiple tooling & infrastructure model/services in cloud had enabled everyone to take advantage to improve the KPIs like MTTR, MTTD & MTTF, so before we answer how, let us try to understand what & why AIOps that’s where real answer is.
What is really AIOps ?
AIOps stands for Artificial Intelligence for IT Operations, as mentioned at the very beginning what it really transforms to, is use of analytics & machine learning to develop a platform which can automate & enhance IT Operations.
IT Operations gets mostly two types of data, one of them is observational data which is mostly comes in the form of logs, events & traces. Second type of data is engagement data which comes as incident tickets and it mostly will have RCA. Nowadays we don’t have any limitation on storing amount of observational data but handling of this data with manual debugging is quite impossible and difficult. It is like searching needle in haystack, so make use of this siloed IT operation data to feed into big data platforms which could be used to draw meaningful outcomes. What are those meaningful outcomes ?

Noise reductions : Lot of times massive volume of events overwhelm the operation team, this cause inefficiency & excessive risk of being missed critical alerts. AIOps can help is feed your observational data and real time data to have meaningful alerting rather than false alerting, which reduces event noise significantly.
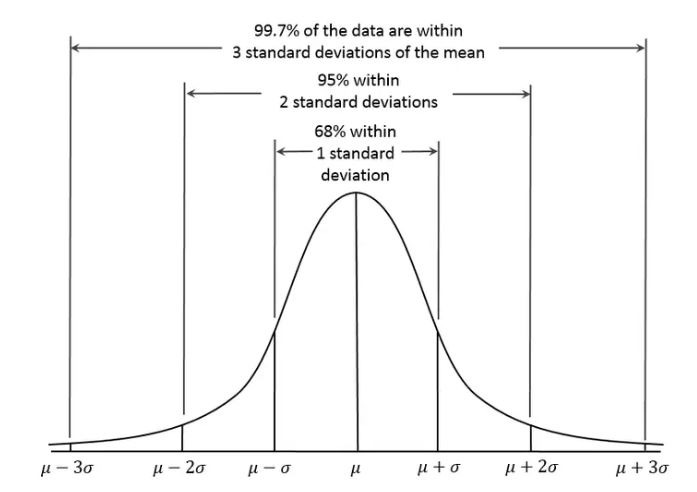
Baseline Creations : Lot of time latency related issues doesn’t comes to attention till users starts reporting otherwise they continue to consider this as new normal. These problems are hard to detect & hard to get reported also, till your systems continues to degrade to such a state where it is in unbearable to user. You need to have baseline models developed which will track system average response times at multiple tiers, which will immediately flag when there is a standard deviation like below. This baseline will be keep on getting revised based on multiple factors like, date time & tiers, so that you have intelligent alerting.
Cause Identification : You have collected engagement data through ticketing system. At the same time you have data related to system failures in your observational data. AI model which can properly correlate both the data and you can establish cause identification.
Automated Actions: Here comes the action part that is where the real value lies of an AIOps. It comes in being able to take automated action on the meaningful observational as well as engagement data insights that are delivered by machine learning and analytics.
Why we need AIOps ?
It is obvious from the above paragraph that we are trying to achieve using AIOps in IT Operation area but let us try to be more specific to KPIs. Since these KPIs ultimately contribute towards the business values and we all are here to serve business needs,
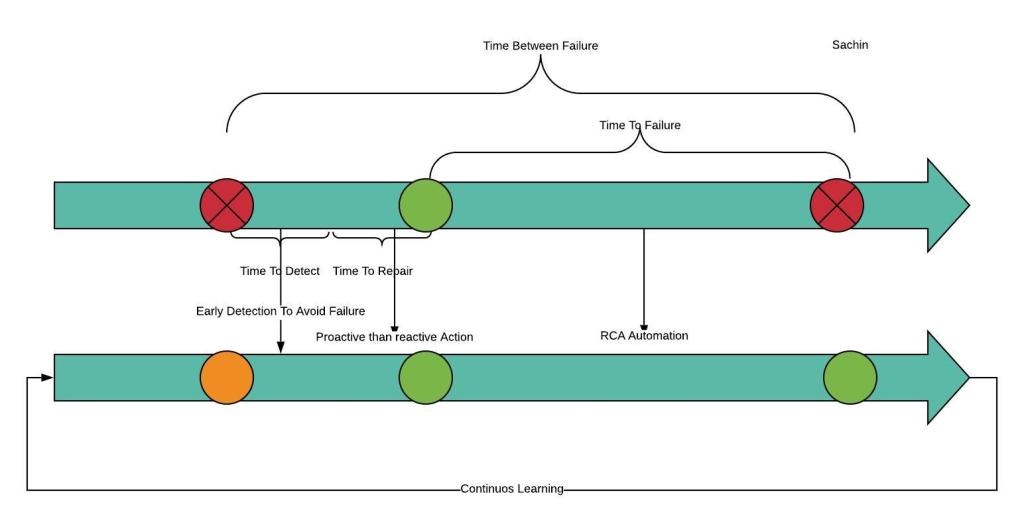
- Reduction in MTTD(Mean Time For Detection) : It refers to the average amount of time it takes to discover an issue. Calculating MTTD is simple. To do so look at the total number of incidents over the course of a period, and calculate the difference between the start of the incident and the time it took the team to detect the incident. This can be calculated by looking at the incidents but actual detection happens outside the incident management tool, which happens after going through the logs or events. The more scattered triggering events, it is hard to detect the problem, which directly affects your MTTD. Best example will be, certain issues related to certain type of attacks on external facing websites. Where you are not sure the volume coming to your application is actual volume or some bots hitting or may be your application/server heartbeat checker went out of control. There are multiple ways to detect such DDoS type attacks but early detection is a must before you start showing 503 errors to end user or showing below screen to actual customer,where customer span on a your website is definitely less than five second. This can happen because of wrong detection or Ops are continuously bombarded with false alarms . As usual humans are tend to take some actions rather than staying in passive state on false alarm that’s where below page gets triggered. At the same tend to ignore real alarming events just because last time he/she learnt that it was false alarm. (It’s like on soccer field goal keeper knows there are 33% chances that ball might come straight to him but still he tends to fall either on left or right because action on the field is better than inaction and that is more cooler)

2. Early detection to increase MTTF(Mean time to failure), is the average amount of time a defective system can continue running before it fails. Time starts when a serious defect in a system occurs and, it ends when the system completely fails. Lot of times even though we have detected the problem we need to make sure system continue to function without impacting end user till we find the permanent solution. Couple of examples in this category, synchronous calls holding connections which causes system running out of resources which demands application architectural changes. In such scenario you want to make sure that end user is not impacted till you fix this. This can be taken care by proactively monitoring and providing additional resources at runtime. At a minimum, AIOps can automatically route alerts and recommended solutions to the appropriate IT teams, or even create response teams based on the nature of the problem and the solution.
3. Increase in MTTR (Mean Time To Resolve) : Mean time to Resolve (MTTR) refers to the time it takes to fix a failed system. It is also known as mean time to resolution. It is a measure of the average amount of time a DevOps team needs to repair an inactive system after a failure. Now that in AIOps models are continuously learning, you are more proactive than reactive. In many cases, it can process results from machine learning to trigger automatic system responses that address problems in real-time before users are even aware they occurred or alerting users.
Conclusion : When every business is looking at digital transformation to deliver the business value. You can’t deliver the solution in today’s dynamic IT landscape with yesterday’s mindset as well as tools. If you think you have successfully implemented DevOps then next step for you is AIOps where you tackle other significant area of IT Ops. If you implement it properly you will be able to concentrate or focus your workforce in other major areas which will contribute towards business growth more. If you are in cloud infrastructure you can definitely march towards NoOps which is where most of the organizations are moving towards. If you are not IT organization then it makes more sense to concentrate on your business than your IT Ops issues.
