

Energy spent equivalent to one smartphone charging to generate this image on Dall-E
In the classic film “Oppenheimer,” which I recently watched I have witness the inner turmoil of Dr. Robert Oppenheimer, the brilliant physicist who led the Manhattan Project during World War II. His invention of the atomic bomb, while a scientific marvel, weighed heavily on his conscience. As we venture into the age of artificial intelligence (AI), we find ourselves at a similar crossroads. Will our pursuit of AI innovation lead to unintended consequences? Are we on the brink of a transformation that will leave us questioning our choices?
As we stand at the forefront of the AI revolution. Our creations—whether large language models (LLMs) or other AI systems—have the potential to reshape industries, improve lives, and unlock new frontiers. Yet, with great power comes great responsibility. We must consider the environmental impact of our AI endeavors. As part of the first generation of heavy AI users, we bear a weighty responsibility. What legacy will we leave for the next generation? Will they inherit a world where AI flourished at the expense of our planet? We must weigh growth against cost, ensuring that our choices align with our values.
Global efforts to control CO2 emissions are commendable. However, we must avoid merely shifting emissions from visible areas to undisclosed ones. Transparency matters. If we’re committed to reducing our carbon footprint, we must account for every kilowatt-hour consumed by AI systems. Data centers—the beating hearts of AI infrastructure—will evolve. Existing centers may adapt to handle AI workloads, but new ones will likely emerge. The question remains: Can we strike a balance between technological progress and environmental stewardship?
As a leader and developer I thought I will share some of my finding and bring awareness to the group of CO2 emmission because of running LLM or AI related workload. Energy consumption is at the heart of the AI dilemma. The more powerful our models become, the more energy they require. Data centers hum with activity, processing vast amounts of information. But this energy demand has a cost: carbon dioxide emissions. The correlation between energy use and emissions is undeniable. Where we source our energy matters—a fact exemplified by certain European data centers that prioritize renewable sources.I have discussed the same in further sections about measuring the CO2 emmision based on location. So I am mostly talking in terms of energy consumption only throughout my article and whereever relevant I have tried to give CO2 references to USA ,South Carolina example.
Some of this information is publically available and some of this information is packaged in the python library with a standard rate.
I have referred to various articles and studies, which are shared in referance and divided my finding into four parts,
Current Consumption and Landscape
As of 04/16/2024 release card of Llama3 released model card release shows, it released during training 2290tCO2eq, which was offset by the program and this is just a training cost what about each query we are going to run on it.

I know tCO2eq numbers are complicated to understand and just to put things in perspective it is equivalent to

I believe all the organizations when they are publishing models they should publish details like above irrespective of opensource or commercial use. Another release information by OpenAI
When comparing the average electricity demand of a typical Google search (0.3 Wh of electricity) to OpenAI’s ChatGPT
(2.9 Wh per request), and considering 9 billion searches daily, this would require almost 10 TWh of additional electricity in a year.
As per the independent study and paper published by the group attached in the link, they propose the first systematic comparison of the ongoing inference cost of various categories of ML systems, covering both task-specific
(i.e. finetuned models that carry out a single task) and ‘general-purpose’ models, (i.e. those trained for multiple tasks),which is as follows.
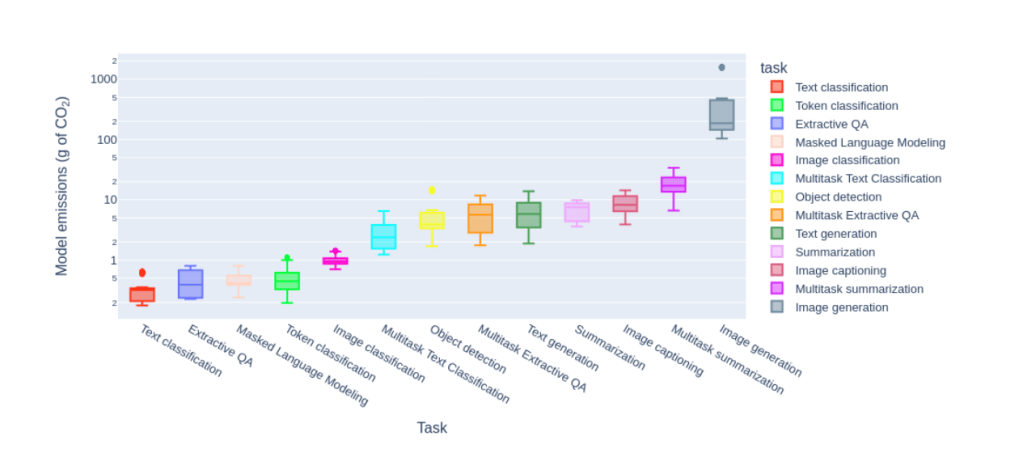
It shows that image generation is quite costlier. So next time when you generate an image on DALL-E or any other think about it. Reference of the paper for the above image tps://arxiv.org/pdf/2311.16863.pdf.
Coming back to overall numbers across the world which was published by International Energy Agency (IAE) report to the most recent figures available, global data centre electricity consumption has grown by 20-40% annually in recent years, reaching 1-1.3% of global electricity demand and contributing 1% of energy-related greenhouse gas emissions in 2022.
Electricity consumption from data centres, artificial intelligence (AI) and the cryptocurrency sector could double by 2026. Data centres are significant drivers of growth in electricity demand in many regions. After globally consuming an estimated 460 terawatt-hours (TWh) in 2022.
Just to put things in perspective an average home consumes close to 10,500 kilowatthours (kWh) of electricity per year.
Expected Growth
Electricity demand in data centres is mainly from two processes, with computing accounting for 40% of electricity demand of a data centre. Cooling requirements to achieve stable processing efficiency similarly makes up about another 40%. The remaining 20% comes from other associated IT equipment.
In 2023, NVIDIA shipped 100 000 units that consume an average of 7.3 TWh of electricity annually. By 2026, the AI industry is expected to have grown exponentially to consume at least ten times its demand in 2023. Data centres’ total electricity consumption could reach more than 1000 TWh in 2026. This demand is roughly equivalent to the electricity consumption of Japan. Below is one of the graph which is published by the IEA.

How we can measure emmission programmatically?
Now that we have a grasp of the current electricity consumption and potential future consumption, we need to determine how much electricity is consumed and the associated carbon emissions when training certain models that utilize resources from either running models locally or in the data center.
Not all data centers have the luxury of abundant green energy. Some are strategically located near fossil fuel-generated electric grids. Why? Because uninterrupted service is paramount. Imagine a data center serving critical applications—financial transactions, emergency services, or cloud infrastructure. It cannot afford downtime. Thus, it tethers itself to the grid, even if that means relying on fossil fuels.
CodeCarbon is a Python library that assists developers in estimating the carbon footprint of their code. It achieves this by measuring the energy consumption needed to execute the code on a specific hardware platform, allowing us to specify the energy source location. In this example, I used an MNIST training model with 5 layers and approximately 693,000 training parameters.


When I executed the program, I utilized a CPU and did not configure it to run on a GPU or TPU. The output of the program displays the CO2 emissions for the location of USA, specifically South Carolina. This calculation was performed using the MNIST dataset, which is a typical dataset with 10 epochs and 693,962 parameters

timestamp=’2024-04-03T17:23:34′, project_name=’codecarbon’, run_id=’929cd0aa-b66d-48ee-80a0-d6e89dcbfd78′, duration=46.22535276412964, emissions=0.0001730959450628993(Emissions as CO₂-equivalents [CO₂eq], in kg), emissions_rate=3.7446105808243794e-06, cpu_power=42.5, gpu_power=0.0, ram_power=4.753046035766602, cpu_energy=0.0005453151732683183, gpu_energy=0, ram_energy=6.0967413836101524e-05, energy_consumed=0.0006062825871044199, country_name=’United States’, country_iso_code=’USA’, region=’south carolina’, cloud_provider=”, cloud_region=”, os=’Linux-6.1.58+-x86_64-with-glibc2.35′, python_version=’3.10.12′, codecarbon_version=’2.3.4′, cpu_count=2, cpu_model=’Intel(R) Xeon(R) CPU @ 2.20GHz’, gpu_count=None, gpu_model=None, longitude=-79.9746, latitude=32.8608, ram_total_size=12.674789428710938, tracking_mode=’machine’, on_cloud=’N’, pue=1.0
Below is the detailed prior output of the program.

More referance link is https://github.com/mlco2/codecarbon
What we can do ?
- Energy-Efficient Hardware:
- Opt for energy-efficient hardware components such as GPUs (Graphics Processing Units) and TPUs (Tensor Processing Units). These specialized chips are designed to accelerate AI workloads while consuming less power.
- Consider using cloud providers that offer green data centers powered by renewable energy sources.
- Model Pruning and Quantization: I will try to cover in future in one of the topic about this topic
- Prune unnecessary connections and layers from neural networks. Smaller models require less computational power during training and inference.
- Quantize model weights to reduce precision (e.g., from 32-bit floating point to 8-bit fixed point). This reduces memory and computation requirements.
- I did a small experiment with changing some of the epochs and and saw if it is possible to reduce the energy consumption without impacting the
- Transfer Learning:
- Instead of training models from scratch, leverage pre-trained models and fine-tune them for specific tasks. Transfer learning significantly reduces training time and resource usage.
- Carbon Neutralization
- Aiming to achieve a net-zero carbon footprint by offsetting emissions through actions such as reforestation, renewable energy adoption, and carbon capture technologies.
Conclusion
In the long term, it’s crucial to consider the source of our energy and whether major organizations are investing in carbon neutralization efforts. Additionally, understanding climate change better is another benefit. However, achieving these goals requires significant investment. As responsible leaders, we must ask tough questions and ensure equal investment in reducing CO2 emissions. When using models, we should release them with a clear understanding of their carbon footprint and hidden costs. As users, we need to weigh the impact of our queries, whether it’s for our kids’ homework or genuine productivity. 🌿🌎
Articles Referred:
