

Why multishot increases opportunity to give correct answer in certain cases?
I’ve been delving into Massive Multitask Language Understanding (MMLU) and reviewing scholarly articles on the assessment of various MMLU methodologies. So stay tuned for MMLU topic also but It became apparent that many of these assessments employ either zero-shot or multi-shot techniques, with the latter often yielding more precise outcomes when a few-shot approach is adopted. Therefore, prior to further discussing evaluations, I find it essential to clarify the concepts of zero-shot and few-shot learning. The remainder of this article will be dedicated to elucidating zero-shot and multi-shot learning, enhancing your comprehension of these methods.
As an illustrative case, I conducted an experiment using Microsoft Copilot. I posed the same mathematical query twice and received two distinct responses at different times, with the latter attempt proving to be more accurate. Screenshots documenting these results are provided for reference.

Here I gave same problem but with two different examples and my prompt was
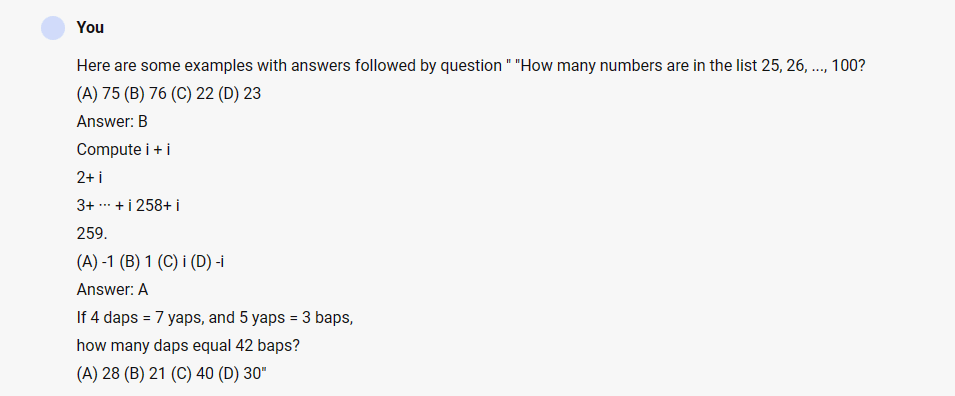

This time I got “C” answer, so what should be approach and why it took a different approach second time and it is accurate.

Let’s delve deeper into the concept of “shots” and their significance. As AI leaders or engineers, understanding terms like Zero-shot and multi-shot is crucial for various topics. Let’s explore what these terms mean and why they matter
What is Zero-shot learning?
Zero-shot learning refers to the ability of a model to perform a task without any specific training examples or labeled data for that task. As you can see in the above example I didn’t add any example which led them to give more wrong answer.
Again zero shot learning is important as it enables models to generalize to new tasks or domains without the need for additional training data. It allows models to leverage their understanding of language and world knowledge to perform tasks they haven’t been explicitly trained on.
What is multishot learning ?
Multi-shot learning refers to the traditional learning paradigm where a model is trained on multiple examples (shots) of each task or class.
Multi-shot learning is important because it allows models to learn task-specific patterns and nuances from a variety of examples. By training on multiple shots of each task, the model can better capture the variability and complexity of real-world data, leading to improved performance on specific tasks.
Why we got proper answer second time and not first time ?
There are multiple reasons for it but major reason could be in our case is
Consideration of Context: In complex mathematical problems, context is crucial for understanding the problem and selecting the appropriate solution method. Multiple shots allow the model to consider different aspects of the problem and incorporate relevant context from previous attempts, leading to more accurate solutions.
Many times, the following factors can also contribute to a more accurate answer
Error Correction: In a multi-shot approach, the model has the opportunity to correct any mistakes made in previous shots. It can learn from its errors and refine its approach to arrive at the correct solution.
Iterative Refinement: Multiple shots allow the model to iteratively refine its understanding of the problem and its solution strategy. With each shot, the model can gather more context and information, leading to a more accurate solution.
Conclusion
As AI users, leaders, and developers, we should consider evaluating a model’s performance based on zero-shot and few-shot scenarios when importing it. So, the next time you seek an answer, consider providing more context—you might witness some magic! However, be wary: even though Copilot can be convincing, it occasionally provides incorrect answers, which can erode your faith in its reliability, as we have seen in the example above. In one of the study, researchers evaluated a chart against GPT-3 using multiple shots for Massive Multitask Language Understanding (MMLU) evaluation.

The findings revealed that accuracy significantly improves with more examples. I didn’t see some of these challenges in GPT 3.5. This experiment is dated April 2024 and may be this will be improved and corrected with time.
Pasting the prompts just for experimentation,
Zero-shot prompt
If 4 daps = 7 yaps, and 5 yaps = 3 baps, how many daps equal 42 baps? (A) 28 (B) 21 (C) 40 (D) 30?
Few-shot prompt
Here are some examples with answers followed by question “How many numbers are in the list 25, 26, …, 100? (A) 75 (B) 76 (C) 22 (D) 23 Answer: B Compute i + i 2+ i 3+ ··· + i 258+ i 259. (A) -1 (B) 1 (C) i (D) -i Answer: A If 4 daps = 7 yaps, and 5 yaps = 3 baps, how many daps equal 42 baps? (A) 28 (B) 21 (C) 40 (D) 30”
